Abstract
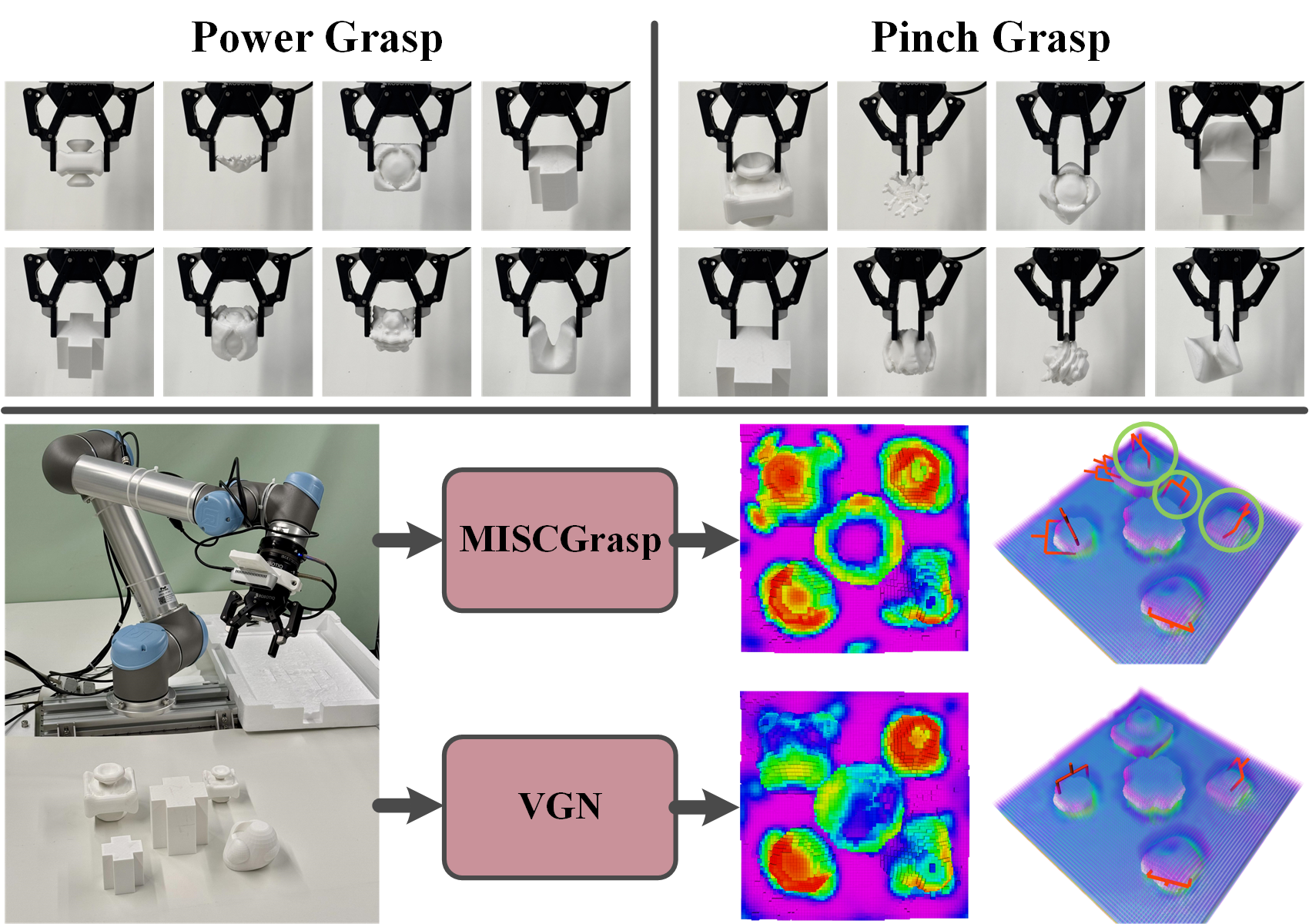
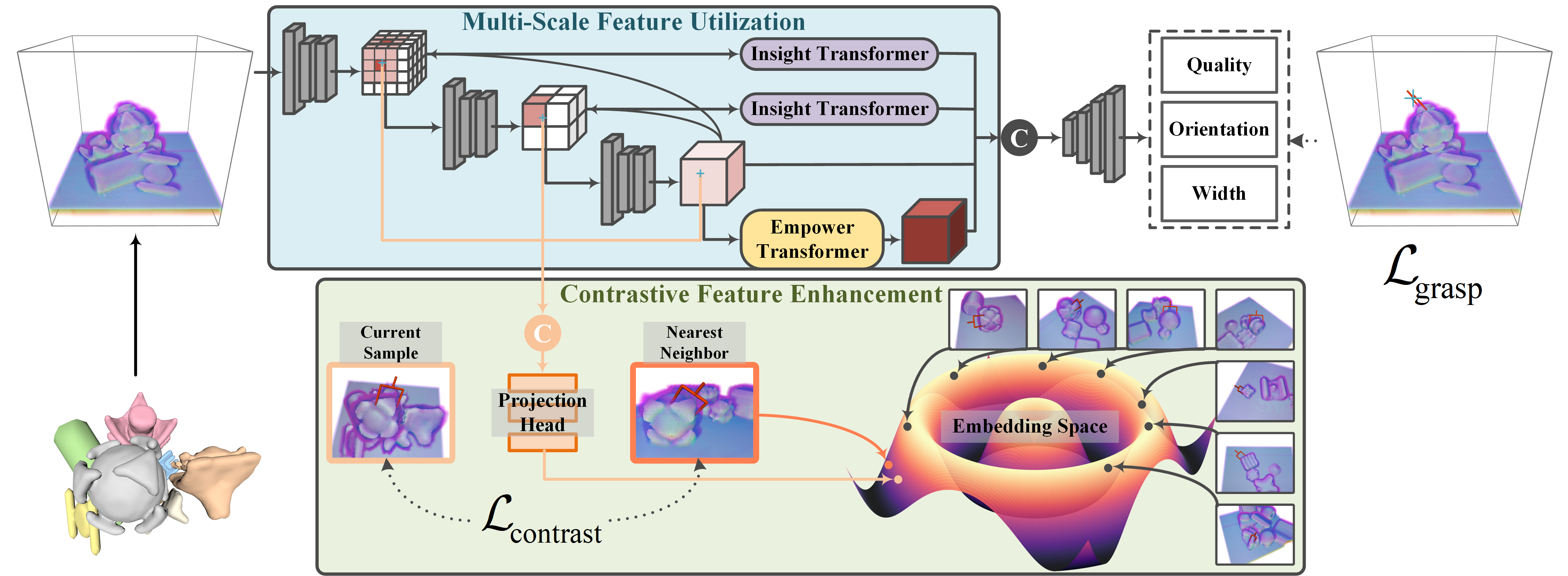
Robotic grasping faces challenges in adapting to objects with varying shapes and sizes. In this paper, we introduce MISCGrasp, a volumetric grasping method that integrates multi-scale feature extraction with contrastive feature enhancement for self-adaptive grasping. We propose a query-based interaction between high-level and low-level features through the Insight Transformer, while the Empower Transformer selectively attends to the highest-level features, which synergistically strikes a balance between focusing on fine geometric details and overall geometric structures. Furthermore, MISCGrasp utilizes multi-scale contrastive learning to exploit similarities among positive grasp samples, ensuring consistency across multi-scale features. Extensive experiments in both simulated and real-world environments demonstrate that MISCGrasp outperforms baseline and variant methods in tabletop decluttering tasks.